前言
随着信息技术的快速发展和教育需求的多样化,如何利用大数据技术为学习者提供个性化、精准化的学习资源,成为现代教育中的一个重要课题。传统的学习资源获取方式存在诸多问题,例如资源冗余、获取方式单一、推荐不够精准等,导致学习效率低下,无法满足学生个性化、智能化的学习需求。因此,开发一个基于Python大数据技术的学习资源推送系统,不仅能够帮助学生高效地获取学习资源,还能提升学习体验,促进学习效果的最大化。
本系统基于大数据分析技术,结合机器学习和推荐算法,旨在为不同学科、不同需求的学生提供个性化的学习资源推荐。通过分析学生的学习行为、兴趣爱好、历史成绩等数据,系统能够精准地推送符合学生需求的学习资源,如视频、文献、习题等,从而实现个性化学习路径的定制。此外,系统还利用Python强大的数据处理和分析能力,对学生数据进行实时挖掘和分析,以动态调整推荐策略,确保推荐内容的及时性与准确性。
本系统采用了现代化的前后端分离架构,前端使用Vue.js实现用户交互界面的设计,后端使用Python的Flask框架进行业务逻辑处理,数据库选择了MySQL进行数据存储。系统具备推荐算法模块、数据分析模块、用户管理模块等核心功能,能够为用户提供实时的学习资源推荐与学习数据分析,帮助学生高效学习并提升学习效果。
系统演示图
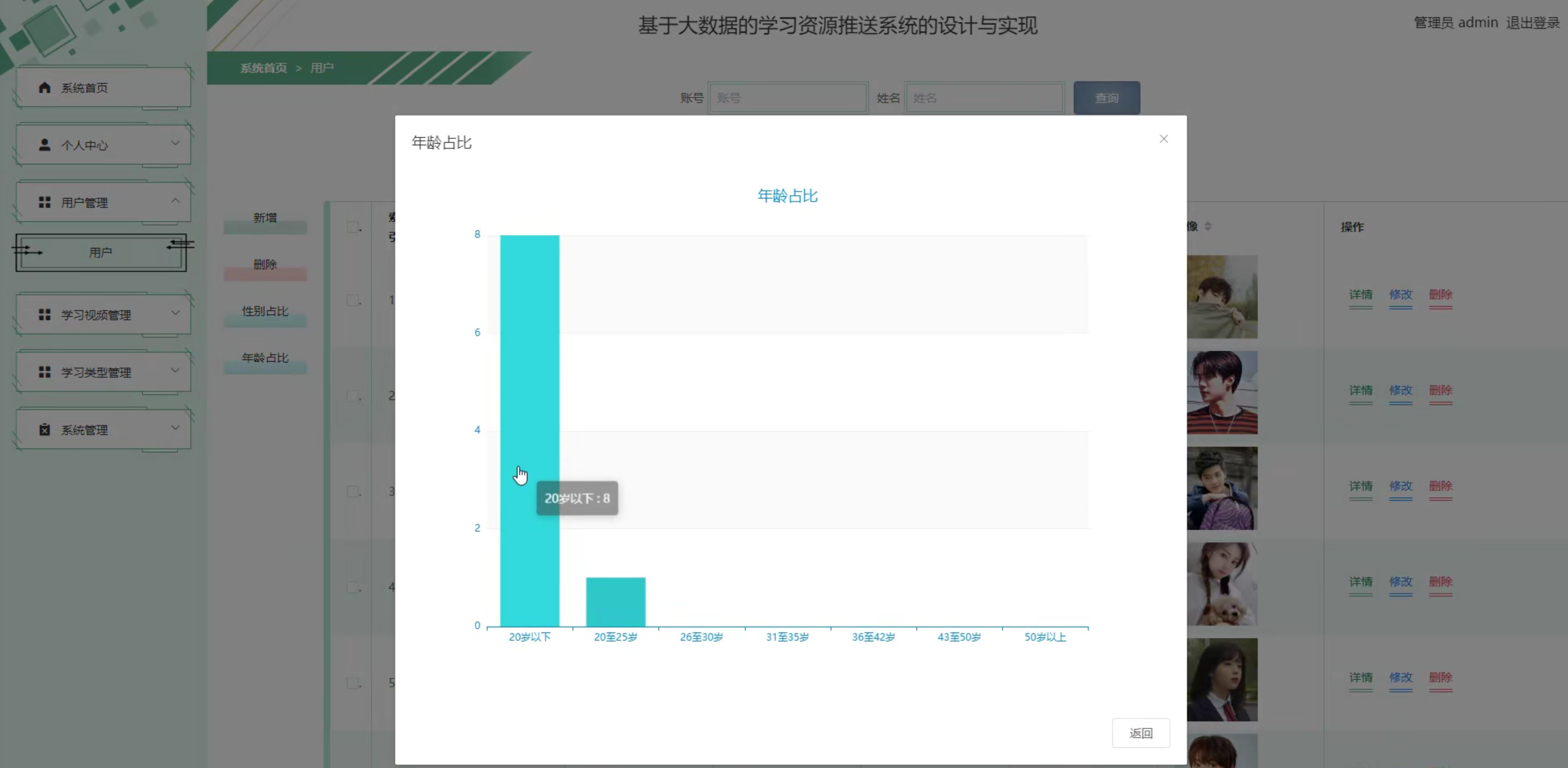

系统测试
为了确保系统的稳定性、可靠性和性能,本系统在开发完成后进行了全面的系统测试。系统测试主要包括功能测试、性能测试、兼容性测试、安全性测试等多个方面,通过模拟实际用户使用场景,确保系统在高负载情况下的正常运行,并保证推送的学习资源符合用户的个性化需求。
系统测试的目标是验证系统是否能够正确、高效地执行预定功能,保证用户在使用过程中能够获得流畅的体验。通过测试,开发团队能够发现系统中的潜在问题,进一步优化系统性能,提高系统的可用性和稳定性。同时,测试阶段也为系统的上线部署提供了数据支持,确保系统能够应对不同环境和高并发访问的挑战。
系统测试目的
- 验证系统功能的完整性与正确性: 通过测试验证系统的各项功能模块是否按预期工作,确保用户能够顺利完成学习资源的查询、推荐、获取等操作。同时,检查各模块之间的接口是否正确,数据传输是否稳定。
- 检测系统性能与负载能力: 在不同的负载条件下,测试系统的响应速度、并发处理能力以及稳定性。特别是在大规模数据处理和高并发请求下,系统是否能够保持较高的性能和响应速度,确保系统的稳定性。
- 确保系统的兼容性: 测试系统在不同操作系统、不同浏览器、不同设备上的兼容性,确保用户无论使用PC端、移动端,还是在不同平台上,都能获得一致的使用体验。
- 确保系统的安全性: 进行安全性测试,检测系统是否存在数据泄露、权限控制不当、恶意攻击等安全隐患。通过测试,确保用户数据的隐私性和安全性,防止系统遭受非法攻击或数据丢失。
- 评估推荐算法的准确性与有效性: 测试推荐算法的精准度,验证推荐结果是否符合学生的兴趣和需求。通过分析学生的学习行为数据和历史成绩,系统应能够准确推送个性化的学习资源,提升学习效果。
- 提高用户体验: 测试系统界面的友好性与易用性,确保用户能够快速上手并高效使用系统。通过用户体验测试,优化系统界面设计,提升用户满意度。
示例代码
from django.http import JsonResponse
from django.shortcuts import render
from .models import Resource, User
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# 计算推荐的学习资源
def recommend_resources(user_interests):
# 获取所有资源
resources = Resource.objects.all()
# 构建资源数据框
resource_data = [{"id": resource.id, "title": resource.title, "category": resource.category, "tags": resource.tags} for resource in resources]
resources_df = pd.DataFrame(resource_data)
# 所有标签的集合
all_tags = list(set(tag for tags in resources_df["tags"] for tag in tags))
# 构建用户的标签向量
user_vector = np.array([1 if tag in user_interests else 0 for tag in all_tags])
# 计算资源的标签向量
resource_vectors = []
for _, row in resources_df.iterrows():
resource_vector = np.array([1 if tag in row["tags"] else 0 for tag in all_tags])
resource_vectors.append(resource_vector)
# 计算用户兴趣与资源之间的余弦相似度
similarities = cosine_similarity([user_vector], resource_vectors)[0]
# 返回与用户兴趣最相似的资源
recommended_indices = similarities.argsort()[::-1]
recommended_resources = resources_df.iloc[recommended_indices]
return recommended_resources
# 路由:获取推荐资源
def recommend(request, user_id):
try:
user = User.objects.get(id=user_id)
except User.DoesNotExist:
return JsonResponse({"error": "User not found"}, status=404)
user_interests = user.interests
recommended_resources = recommend_resources(user_interests)
# 构建推荐资源的结果
recommendations = [{"id": row["id"], "title": row["title"], "category": row["category"]} for _, row in recommended_resources.iterrows()]
return JsonResponse({"recommended_resources": recommendations})
联系作者
[start-plane type=”1″]网站首页或者导航菜单栏点击联系我们[/start-plane]


最新评论
666!
买了可以帮忙修改吗,博主?
咨询定制
挺好
代码是完整的,可以入手,兄弟们
博主帮忙远程部署的,速度非常止之快,效率了🤞
不错
毕设答辩已过,感谢作者耐心指导